
#AgentAnecdotes: When extra thinking only make things worse


I want to occasionally share stories of full Agentic coding sessions. I feel like it's very hard for me to calibrate my experiences against others, and I bet others are feeling the same way. I don't know if I should be doing more learning or more teaching, so my usual way to deal with that uncertainty is more yapping. I'm hoping being transparent with my experiences will help others too! These will accumulate over at #agentanecdotes. BTW, if you want to stay on top of these, I'm using Ghost for my CMS, which supports email addresses and "memberships", but that's silly. You should just use RSS.
I'm going to try to follow a consistent structure: Context, tl;dr, Insights, Deep Dive.
Context
In my Practical guide to Agentic Engineering, I wrote about my process for code reviews. I think it's a great p90 workflow, maybe even p99, and I stand behind it. I want to tell a story about when the process fails and I don't have a solution for it that removes my experience and judgement from the loop.
In 2026, it's really amusing watching studies critical of LLM performance trickle out. It's not that they're wrong, it's that they miss the point. Nobody (should be) using LLMs directly without a harness, and harness cleverness (typically classic software engineering cleverness, little to do with AI), is where the majority of innovation is happening. Arguably, the newest frontier model versions (that are currently coming monthly), are just encapsulating the same introspection/eval loop internally. And then within "user space", we are just adding more of our own loops with stuff like ralph. (I'm not, but you might be.)

The reasoning actually holds up to scrutiny: with extra iterations with fresh context, every new pass goes deeper and finds new insights. This improves the code, covers more edge cases, and results in fewer bugs. Until it doesn't.
The current (April 2026) generation of agentic coding tools over-index on defensive programming. They are way too eager to do boundary checks at every level and are obsessed with unhandled exceptions, usually looking at too narrow a scope. This is "fine" for business logic, but can get kind of unbearable with infrastructure code that is trying to deal with anything resembling caches, connection management, or god forbid concurrency. Here's a scenario where I was really unhappy with where my agent ended up, which caused me to throw everything out and start over.
tl;dr
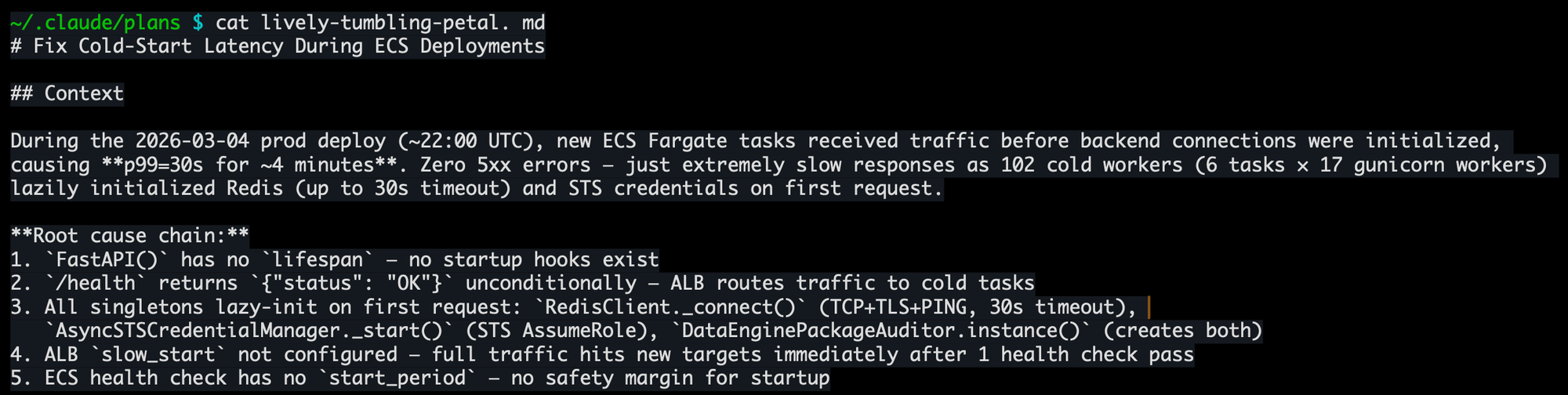
A few weeks back, I deployed one of our services (Gunicorn web server on AWS ECS) to prod, and saw a longer availability drop than I wanted. Claude and I root-caused it to lazy initialization: our Gunicorn workers were accepting traffic before their backends (Valkey, STS credentials, database connections) were warm. This caused every first caller to each worker to pay a 30+ second initialization cost, and timing out.1. Simple enough fix: add a FastAPI lifespan handler to pre-initialize everything, plus some tuning of ELB and ECS deployment settings to give the inits some space to breathe. 3-4 changed files, straightforward plan, gets the job done.
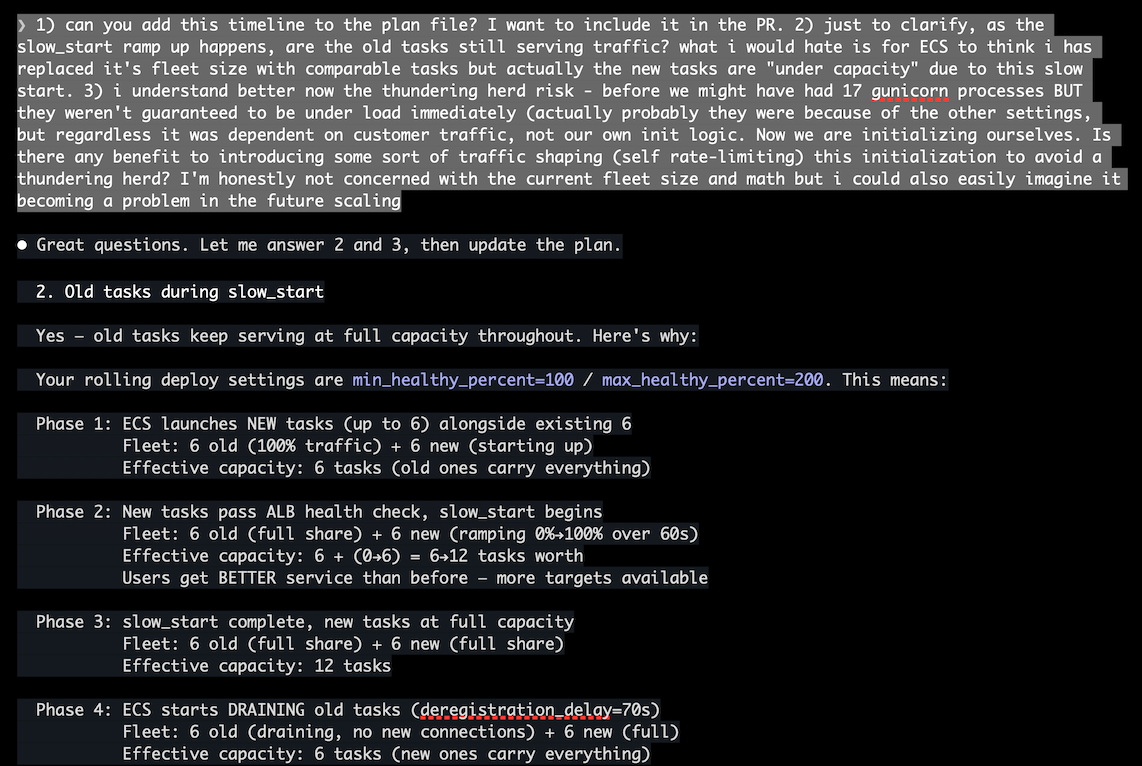
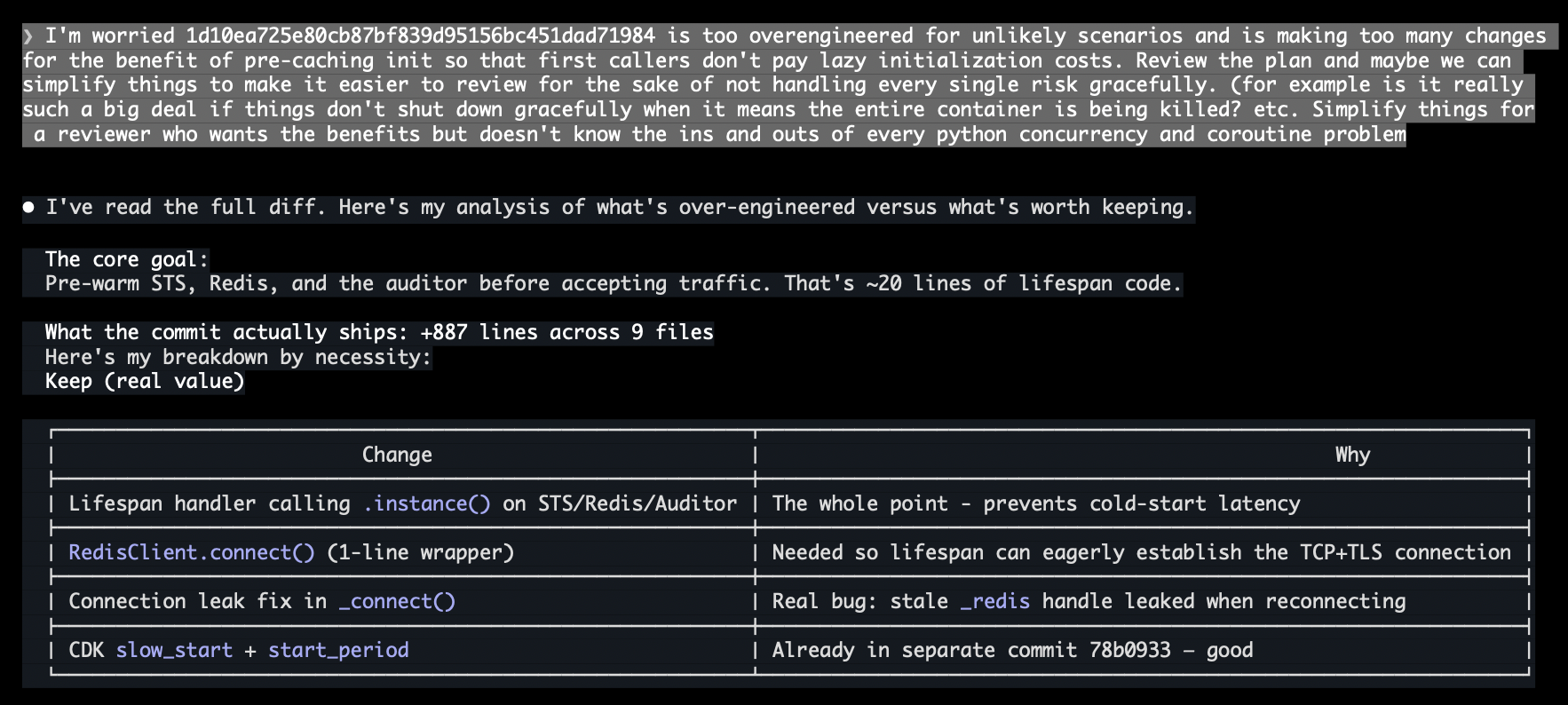
My review workflow ran as designed. Claude implemented the plan, kicked off a clean-context code review sub-agent, the reviewer filed findings, the main agent evaluated and created tasks, I agreed with them, and approved another cycle. This happened two more cycles. By the third time I was reviewing the status qo, the code had ballooned with async-safe double-checked locking, graceful shutdown orchestration, connection leak defenses, STS context manager lifecycle tracking, and warmup jitter for thundering herd prevention at a fleet scale we don't have. Each individual change was defensible. The aggregate was absurd. I wrote a big rant, chastized Claude for all the over-engineering, and told it to start over. The final result was 10% of the code, and I probably could've done it by hand.
Insights
Now, before someone screenshots the end of that last paragraph to dunk on me for having AI derangement syndrome to gleefully ignore my own 20 years of software engineering experience, let's start with some meta-insights:
- Even anecdotes of failure are illuminating. Learning what doesn't work sometimes takes longer than learning what does.
- High reward strategies carry risk. I ignored 3 full iterations of autonomous agent review-iteration before I spotted the overengineering. Could I have noted it right away? Mostly (see #3). But I wasn't paying attention to the first couple of cycles, by design. I do other things in parallel during this workflow, but do a focused review at the end. My working model is optimized for minimizing scenarios that this post is about, and so most of the time it is perfectly justifiable to let Claude self-corrects its own indiscretions in a loop.2
- Along the way, I was also asking Claude to clarify and explain the choices it was making. This is crucial to agentic engineering. I am learning, as I'm steering. I am trusting, but gathering the knowledge to verify, and to come out of the experience with understanding. Of Python's GIL, of FastAPI's lifespan events, of ALB's slow starts. I started getting the PR ready for my reviewer, considered what her first impression would be of this monster diff, and my spidey sense went off. But I had accumuluted enough cortext context (aka my meat 🧠) to have some opinions on what to dump, and what to keep. I did not have that at the start of the session.
OK, but what about insights on AI coding itself? I have one massive one: more model thinking wouldn't have helped here. This isn't about Claude, or Opus, or Anthropic, or LLMs, or AGI.
There is no agentic solution for this. There's no CLAUDE.md instruction, no skill, no command, no review workflow that could have prevented the over-engineering. Because the over-engineering happened through a process that was working exactly as designed. Each individual review finding was correct. Each individual fix was reasonable. The only problem was the aggregate, and evaluating the aggregate requires subjective judgment about what matters for this specific system in this specific operational context.
This is a limit, and this limit isn't going away no matter how smart the models get. Because the decisions are subjective. This service didn't need graceful shutdown or async-safe double-checked locking. But in a slightly different context - like a long-running database process that manages connection pools, every single one of those defensive improvements would've been right. The agent doesn't know, and can't know, because the distinction isn't in the code. My Claude Code Tamagotchi knows it too:

This is ultimately why, no matter how we do it, humans are still essential to the loop. The point now is how to get to this point as quickly as possible. Sometimes that can happpen upfront, other times it will require some iterations and research and dead ends, but the goal is the same.

Deep Dive
I lied this time. I'm not going to bore you with the full session walkthrough. It's interesting...I backed up the entire exchange. But at some point you hit diminishing returns on learning from reading. Maybe next time!
Footnotes
1 I'll save my rant about Python's whole threading model for another day. All you need to know (which is only a little less than what I know myself at this point) is that Python is historically single-threaded but web servers like Gunicorn kick off a bunch of processes as a "thread pool". Works well enough, but also means no sharing of in-memory caches or connection pools.
2And yes, I am going to continue doing my human review at the end. This isn't vibe coding. We don't do that around here.



